 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch-E1: Self-Distillation Drives Self-Evolution in Search-Augmented Reasoning
May 21, 2026Post-training has become the dominant recipe for turning a language model into a competent search-augmented reasoning agent. A line of recent work pushes its performance further by adding elaborate machinery on top of this standard pipeline. These augmentations import external supervision from stronger external systems, attach auxiliary modules such as process reward models or retrospective critics, restructure the rollout itself with tree search or multi-stage curricula, or shape the reward with hand-crafted bonuses and penalties. Each addition delivers a measurable gain, but each also inflates the training pipeline and ties the recipe to resources or designs that may not always be available. We take a step back and ask whether any of this machinery is actually necessary, and propose Search-E1, a self-evolution method that lets a search-augmented agent improve through only vanilla GRPO interleaved with offline self-distillation (OFSD). After each GRPO round, the policy rolls out on its own training questions. A token-level forward KL objective then aligns the policy's inference-time distribution to its own distribution under a privileged context that exposes a more efficient sibling trajectory. Despite this simplicity, the procedure naturally provides dense per-step supervision. On seven QA benchmarks, Search-E1 reaches $0.440$ average EM with Qwen2.5-3B, surpassing all open-source baselines at both scales. Code and complete version will be made public soon.
SD-Search: On-Policy Hindsight Self-Distillation for Search-Augmented Reasoning
May 18, 2026Search-augmented reasoning agents interleave internal reasoning with calls to an external retriever, and their performance relies on the quality of each issued query. However, under outcome-reward reinforcement learning, every search decision in a rollout shares the same trajectory-level reward, leaving individual queries without step-specific credit. Recent process-supervision approaches address this gap by drawing step-level signals from outside the policy, relying either on a much larger teacher model, or on sub-question annotations produced by a stronger external system. In contrast, we propose SD-Search, which derives step-level supervision from the policy itself through on-policy hindsight self-distillation, requiring neither an external teacher nor additional annotations. In SD-Search, a single model plays two roles that differ only in conditioning: a student that sees only the context available at inference time, and a teacher that additionally conditions on a compact hindsight block summarizing the search queries and final outcomes of a group of rollouts sampled from the same question. Since the teacher knows how each rollout unfolded and which ones succeeded, its query distribution implicitly marks which decisions were worth making, and the student is trained to recover this behavior by minimizing the token-level Jensen--Shannon divergence to the teacher at search-query positions. This layers a dense, step-level signal on top of GRPO's coarse trajectory reward. Crucially, this signal is produced by the policy itself within the standard RL training loop, without external model inference, auxiliary annotation pipeline, or additional training stage.
IG-Search: Step-Level Information Gain Rewards for Search-Augmented Reasoning
Apr 16, 2026Reinforcement learning has emerged as an effective paradigm for training large language models to perform search-augmented reasoning. However, existing approaches rely on trajectory-level rewards that cannot distinguish precise search queries from vague or redundant ones within a rollout group, and collapse to a near-zero gradient signal whenever every sampled trajectory fails. In this paper, we propose IG-Search, a reinforcement learning framework that introduces a step-level reward based on Information Gain (IG). For each search step, IG measures how much the retrieved documents improve the model's confidence in the gold answer relative to a counterfactual baseline of random documents, thereby reflecting the effectiveness of the underlying search query. This signal is fed back to the corresponding search-query tokens via per-token advantage modulation in GRPO, enabling fine-grained, step-level credit assignment within a rollout. Unlike prior step-level methods that require either externally annotated intermediate supervision or shared environment states across trajectories, IG-Search derives its signals from the policy's own generation probabilities, requiring no intermediate annotations beyond standard question-answer pairs. Experiments on seven single-hop and multi-hop QA benchmarks demonstrate that IG-Search achieves an average EM of 0.430 with Qwen2.5-3B, outperforming the strongest trajectory-level baseline (MR-Search) by 1.6 points and the step-level method GiGPO by 0.9 points on average across benchmarks, with particularly pronounced gains on multi-hop reasoning tasks. Despite introducing a dense step-level signal, IG-Search adds only ~6.4% to per-step training wall-clock time over the trajectory-level baseline and leaves inference latency unchanged, while still providing a meaningful gradient signal even when every sampled trajectory answers incorrectly.
OneSearch-V2: The Latent Reasoning Enhanced Self-distillation Generative Search Framework
Mar 25, 2026Generative Retrieval (GR) has emerged as a promising paradigm for modern search systems. Compared to multi-stage cascaded architecture, it offers advantages such as end-to-end joint optimization and high computational efficiency. OneSearch, as a representative industrial-scale deployed generative search framework, has brought significant commercial and operational benefits. However, its inadequate understanding of complex queries, inefficient exploitation of latent user intents, and overfitting to narrow historical preferences have limited its further performance improvement. To address these challenges, we propose \textbf{OneSearch-V2}, a latent reasoning enhanced self-distillation generative search framework. It contains three key innovations: (1) a thought-augmented complex query understanding module, which enables deep query understanding and overcomes the shallow semantic matching limitations of direct inference; (2) a reasoning-internalized self-distillation training pipeline, which uncovers users' potential yet precise e-commerce intentions beyond log-fitting through implicit in-context learning; (3) a behavior preference alignment optimization system, which mitigates reward hacking arising from the single conversion metric, and addresses personal preference via direct user feedback. Extensive offline evaluations demonstrate OneSearch-V2's strong query recognition and user profiling capabilities. Online A/B tests further validate its business effectiveness, yielding +3.98\% item CTR, +3.05\% buyer conversion rate, and +2.11\% order volume. Manual evaluation further confirms gains in search experience quality, with +1.65\% in page good rate and +1.37\% in query-item relevance. More importantly, OneSearch-V2 effectively mitigates common search system issues such as information bubbles and long-tail sparsity, without incurring additional inference costs or serving latency.
KuaiSearch: A Large-Scale E-Commerce Search Dataset for Recall, Ranking, and Relevance
Feb 12, 2026E-commerce search serves as a central interface, connecting user demands with massive product inventories and plays a vital role in our daily lives. However, in real-world applications, it faces challenges, including highly ambiguous queries, noisy product texts with weak semantic order, and diverse user preferences, all of which make it difficult to accurately capture user intent and fine-grained product semantics. In recent years, significant advances in large language models (LLMs) for semantic representation and contextual reasoning have created new opportunities to address these challenges. Nevertheless, existing e-commerce search datasets still suffer from notable limitations: queries are often heuristically constructed, cold-start users and long-tail products are filtered out, query and product texts are anonymized, and most datasets cover only a single stage of the search pipeline. Collectively, these issues constrain research on LLM-based e-commerce search. To address these challenges, we construct and release KuaiSearch. To the best of our knowledge, it is the largest e-commerce search dataset currently available. KuaiSearch is built upon real user search interactions from the Kuaishou platform, preserving authentic user queries and natural-language product texts, covering cold-start users and long-tail products, and systematically spanning three key stages of the search pipeline: recall, ranking, and relevance judgment. We conduct a comprehensive analysis of KuaiSearch from multiple perspectives, including products, users, and queries, and establish benchmark experiments across several representative search tasks. Experimental results demonstrate that KuaiSearch provides a valuable foundation for research on real-world e-commerce search.
De-Pois: An Attack-Agnostic Defense against Data Poisoning Attacks
May 08, 2021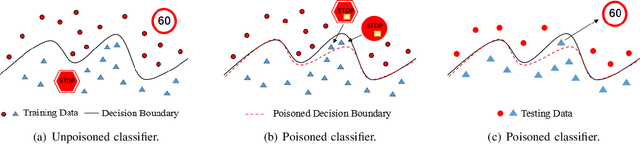
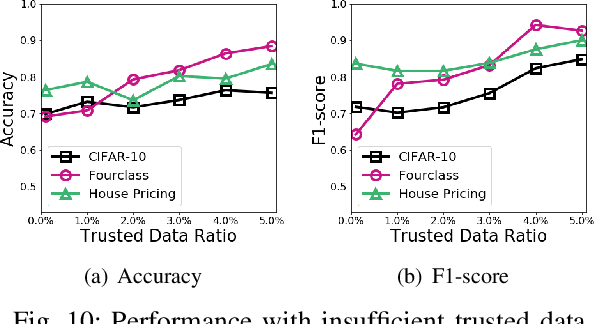
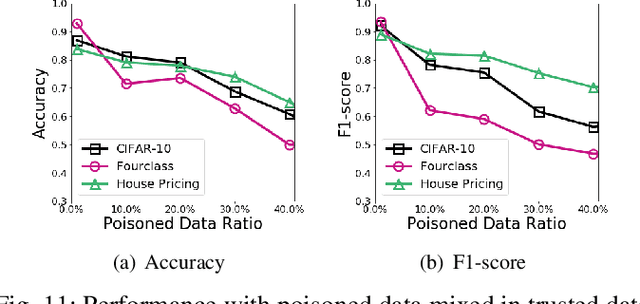
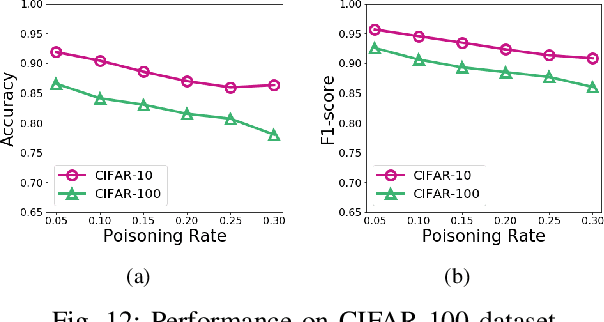
Machine learning techniques have been widely applied to various applications. However, they are potentially vulnerable to data poisoning attacks, where sophisticated attackers can disrupt the learning procedure by injecting a fraction of malicious samples into the training dataset. Existing defense techniques against poisoning attacks are largely attack-specific: they are designed for one specific type of attacks but do not work for other types, mainly due to the distinct principles they follow. Yet few general defense strategies have been developed. In this paper, we propose De-Pois, an attack-agnostic defense against poisoning attacks. The key idea of De-Pois is to train a mimic model the purpose of which is to imitate the behavior of the target model trained by clean samples. We take advantage of Generative Adversarial Networks (GANs) to facilitate informative training data augmentation as well as the mimic model construction. By comparing the prediction differences between the mimic model and the target model, De-Pois is thus able to distinguish the poisoned samples from clean ones, without explicit knowledge of any ML algorithms or types of poisoning attacks. We implement four types of poisoning attacks and evaluate De-Pois with five typical defense methods on different realistic datasets. The results demonstrate that De-Pois is effective and efficient for detecting poisoned data against all the four types of poisoning attacks, with both the accuracy and F1-score over 0.9 on average.